Ref.
Ghodrati, Soroush, et al. "Planaria: Dynamic architecture fission for spatial multi-tenant acceleration of deep neural networks." 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020.
본 논문은 진행중인 Auto Driving 관련 프로젝트의
Insight를 위해 읽었기 때문에
필요한 내용만 간추려 요약하였습니다.
Abstract
Deep Neural Networks(DNNs)이 실생활의 많은 Application에서 사용됨에 따라 빠른 속도로 산업과 시장에 적용되었습니다. 기술이 발전함에 따라, *Inference-as-a-Service(INFaaS)를 제공하는 Cloud 인프라와 AI accelerator는 업계에 혁신적인 변화를 가져 왔습니다. 그 결과 대부분의 INFaaS 기반 Accelerators들은 (ex. Google's TPU, NVIDIA T4, Microsift Brainwave 등) 많은 Real-life application들의 중추적인 역할을 담당하게 되었습니다.
Multi-tenancy 환경에 대한 수요가 Datacenter의 물리적 확장을 이끌었지만, 다양한 Application의 방대한 data들을 효율적으로 처리하기 위하여 단순히 가속기의 수를 늘리는 것은 경제적이지 않습니다. 단순히 더 빠른 속도와 효율성을 위한 경쟁으로 인해 Multi-tenancy 환경에 적합한 DNN Accelerator를 설계하는 것에 대해서는 아직 많은 연구가 필요한 상황입니다. 따라서 이번 연구에서 'Dynamic architecture fission(break)' 으로 불리는 새로운 기술을 적용하였습니다. 위의 기술을 적용하여 여러 DNN models들을 새로운 Demension들로 동적으로 분할하고 재연결했으며, Multitenancy 에 적합한 새로운 DNN runtime engine인 'Planaria' 를 제안합니다.
위의 새로운 Microarchitecture를 통하여 동일한 Hardware 공간에서 여러 DNN Inference serveices들을 공간 효율적으로 배치할 수 있으며, Multi-tenant DNN을 가속할 수 있습니다. 이를 위하여 먼저, DNN 가속을 위하여 분할 가능한 omni-directional systolic array를 찾습니다. 그 다음, Systolic array 기반의 DNN accelerator가 정상적으로 분할 될 수 있도록 Planaria만의 독특한 구성을 사용합니다. (On-chip memory과 Computer resource 간의 상호 연결 구성)
Architecture 수준에서의 분할과 연결 유연성은 Task 기반 Scheduling이 더 자유롭게 이루어질 수 있도록 합니다. 이를 통해 Scheduler는 가속기를 Server load, DNN topology, task priority 등을 고려할 수 있게 됩니다. 이를 통하여 가속기에서 Multi DNN 실행 시 Throughput, Utilization, QOS, Fairness 등을 향상 시킬 수 있습니다.
*INFaaS
: Inference as a service provides a core set of common functionality required to develop various context-aware apps
: INFaaS 안에 사용 가능한 Solution이 존재한다면 개발자는 Training data를 직접 넣지 않아도 되며, 구체적인 model을 구축하지 않아도 됩니다. 자세한 내용은 아래 그림을 참조해 주세요.

Introduction
인공지능 산업이 발전함에 따라 더 빠르고 효율적인 DNN execution의 필요성이 증가했고 이는 DNN Accelerator의 등장으로 이어졌습니다. (Google의 TPU, NVIDIA의 T4, Microsoft의 Brainwave 등) 하지만 빠른 속도와 효율성 증대를 위한 ‘arms race’라 불리는 market에서의 경쟁에 치중한 나머지, Multi-tenancy 환경에 최적화 된 Microarchitecture를 설계하는 것에 대한 연구와 노력이 부족한 상황입니다. 조사에 따르면 Datacenter 에서의 Hardware utilization 은 50%정도에 그치며, 이는 심각한 자원의 낭비를 초래합니다. 때문에 본 논문에서는 ‘Planaria’라는 이름의 새로운 microarchitecture mechanism을 제안합니다. 이어 설명하겠지만 Planaria는 분할된 Logical DNN Accelerators를 통한 Multi-tenant 가속 기법으로 유연한 Task scheduling을 가능하게 하여 Throughput, hardware utilization, QOS, Fairness 등에 최적화된 새로운 메커니즘을 제안합니다. 이를 통해 하나의 가속기 안에서 Multi DNNs Execution을 가능하게 하며 동시에 여러 DNN Task들을 처리할 수 있습니다.
* 참고로 arms race란 군비 경쟁을 일컫는 말로 위의 상황에서는 단순히 더 많은 돈을 들여 더 크고 다양한 가속기를 맹목적으로 도입하는 상황을 설명합니다.

1999년도, Powerful한 Accelerator인 GPU가 최초로 세상에 나왔습니다. 그 후, 2001년도에는 GPU를 그래픽 처리 뿐만이 아니라, General Purpose computing을 위해 사용한다는 GPGPU라는 개념이 등장했습니다. 2001년도에서 2009년도로 넘어가며 Hardware resource utilization에 대한 문제가 처음으로 제기되었으며 이를 개선하기 위해 Multi tenancy 개념을 도입하였습니다. 하여, 2009년 최초의 Multi tenancy GPU인 Fermi architecture가 등장했습니다. 2014년에는 Spatial multi-tenancy에 관한 150여개의 연구가 발표되었으며 2014년에는 인공지능 열풍에 힘입어 ML Accelerator 설계에 관현 800여개의 연구들이 발표되었습니다. 하지만 이 기간동안의 연구는 실제 가속기에서의 Resource utilization 문제와 Cost effective adoption이 가장 중요한 조건으로 고려되지 않았습니다. 2020년이 되어서야 이 부분을 고려해 설계해야한다는 주장이 제시되며 위의 문제를 고려한 2가지 정도의 논문이 발표되었습니다. 하지만 2020년에 제시된 Temporal Multi tenant 에 관한 연구는 하드웨어 Utilization 문제를 해결하기 위한 근본적인 해결책이 아닙니다. 왜냐하면 한 시점에서 오직 하나의 Task만이 Dispatch되어 처리될 수 있기 때문입니다.
하여 본 연구에서 위 문제에 대한 근본적인 해결책을 제시하기 위하여, Dynamic architecture fission을 통한 새로운 Spatial Multi-tenancy DNN 가속기인 'Planaria'를 제안합니다.
Insight
i) Concept & Overview

: Planaria의 기본적인 concept은 하나의 DNN accelerator를 여러 개의 Logical DNN accelerator들로 분할하여 가속한다는 것 입니다. Ready queue에 대기하고 있는 여러 DNN model들은 다시 여러 DNN Task로 분할되어 각 Logical DNN Accelerator에 할당되게 됩니다. 할당된 여러 Task들은 가속기에서 동시에 실행될 수 있으며, 이를 통해 한 번에 하나의 DNN model만 실행될 때 발생하는 Lower utilization 문제를 해결하고 Multi DNN execution이 가능한 환경을 조성합니다.

: 위의 두 그림은 Multi DNN Acceleration을 동시에 실행할 때의 상황을 묘사하고 있습니다. Planaria의 Key idea는 바로 동일한 하드웨어에서 다양한 DNN 추론들을 분해하고 적합한 장소에 배치하는 Dynamic fissioning(분해) 기법입니다. 이는 하나의 가속기 내에서 일어나는 작업입니다. 일반적으로 DNN 가속기는 on-chip memory bank들과 Computing resource인 MAC unit들로 구성되어 있습니다. 위의 그림에서 M과 C가 위의 요소들을 나타내는 그림입니다.
Figure 3의 (a)는 우선순위가 높은 DNN task를 처리하거나 QOS 제약 조건이 큰 경우에 처리되는 상황을 설명합니다. 그림의 중간과 오른쪽에 배치되어 있는 Figure 4의 (b)와 (c)의 경우는 multiple DNN task들이 분할되어 재결합한 구조를 설명합니다. 이는 그림에서 Logical accelerator라는 용어로 표현하고 있으며 이를 통해 DNN들이 높은 Throughput 을 유지하며 QOS 제약을 충족시킬 수 있습니다. (b)는 두 개의 Logical accelerator들을 사용해 2개의 DNN model들을 동시 가속한 상황을, (c)는 세 개의 Logical accelerator들을 사용해 3개의 DNN model들을 동시에 가속한 상황을 묘사하고 있습니다.
ii) Architecture Design
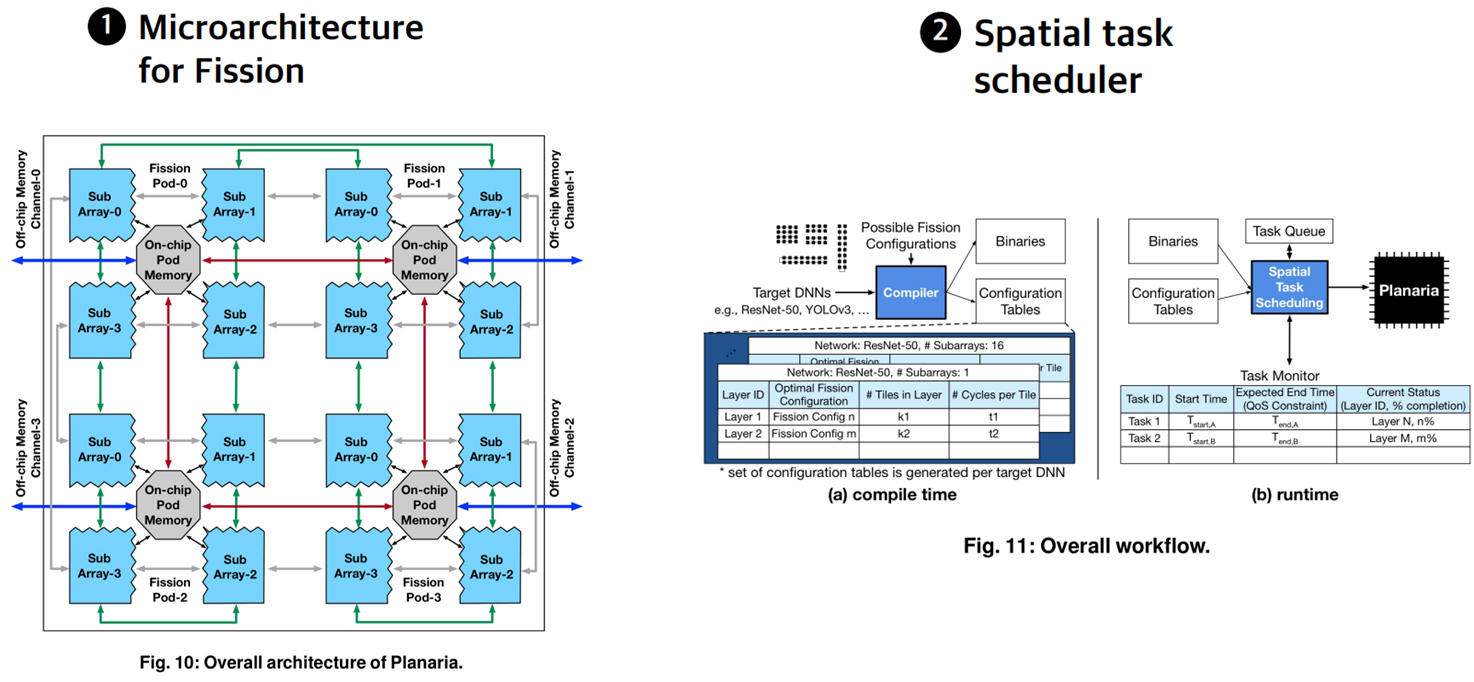
: 앞에서 설명한 Dynamic fission을 통한 Multi DNN 가속을 위해서는 2 가지의 Main components들이 필요합니다. 먼저 Dynamic fission을 수행하기 위한 microarchitecture를 설계해야 하며, 두 번째로 Dispatched된 task들을 Hardware resource에 할당하기 위한 Spatial task scheduler가 필요합니다.

: Dynamic fission을 위한 microarchitecture 설계의 목표 4가지와 한계 2가지 입니다.
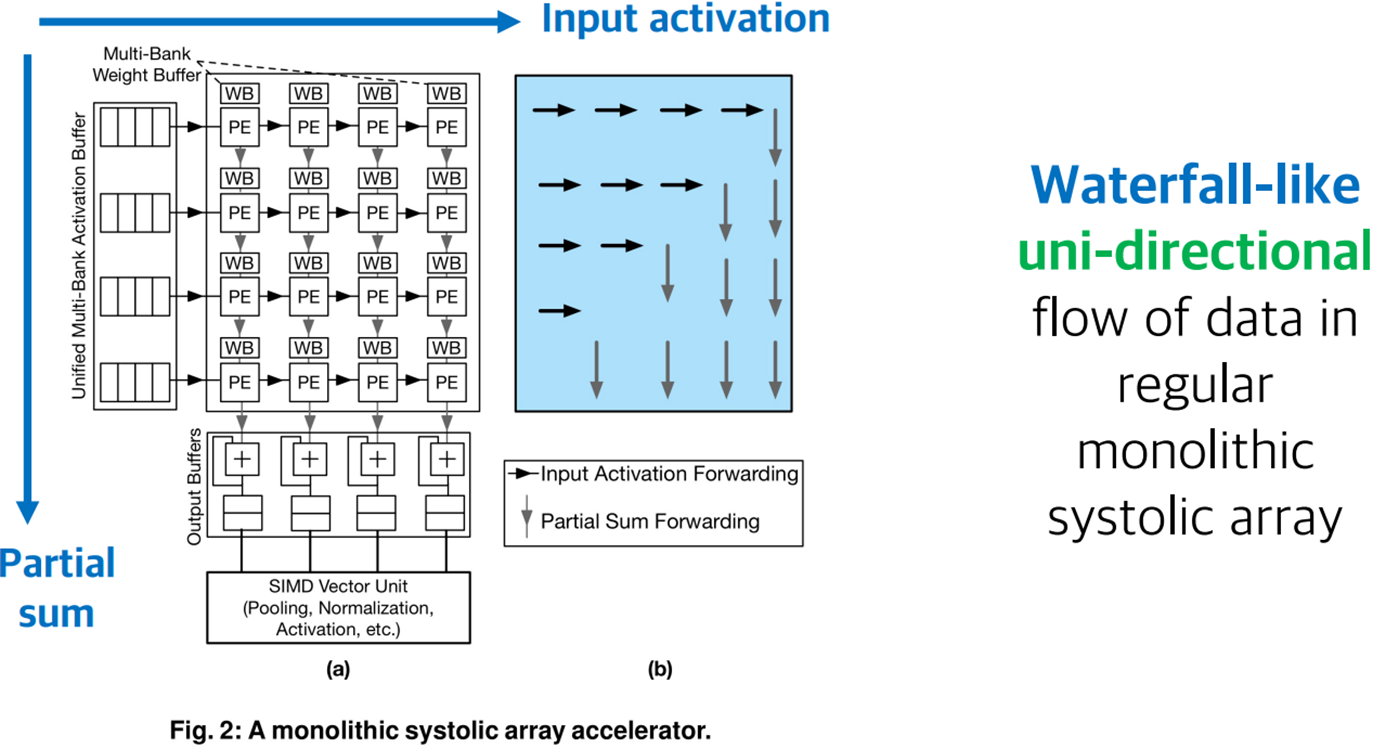
: 위의 그림은 일반적인 Systolic array를 설명하는 그림입니다. Systolic array는 여러 PE들이 하나의 집합으로 연결되어 있으며 Input과 Output을 위한 Buffer가 존재합니다. 이 구조에서는 Data가 오직 한 방향으로만 흐를 수 있다는 제한 조건이 있습니다. 예를 들어 Input activation part에서는 데이터들이 왼쪽에서 오른쪽으로만 이동하고, Partial sum을 위해서는 오직 위에서 아래로만 데이터가 이동하게 됩니다.
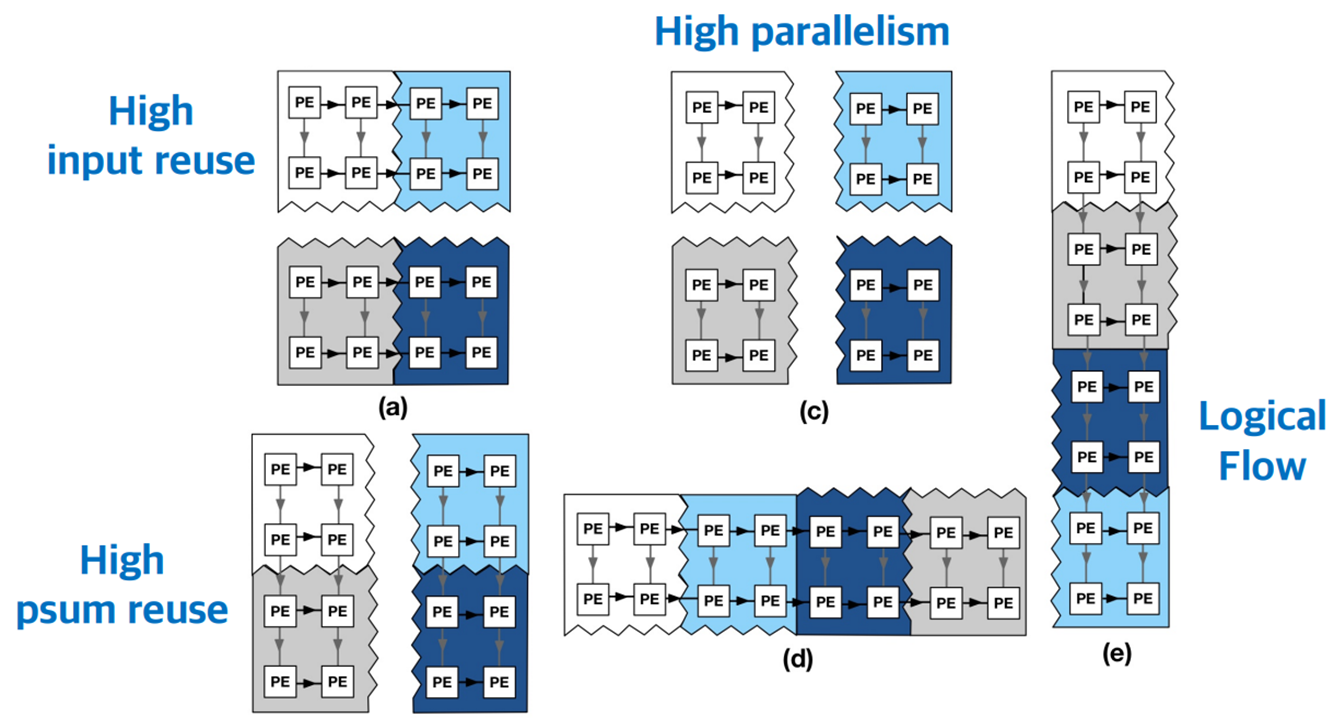
: 하여 Planaria architecture에서는 데이터의 흐름이 단방향이 아니라 모든 방향으로 이어질 수 있도록 기존의 Systolic array를 분할하고 재결합 하는 방법이 적용되었습니다. 위의 그림들은 다양한 상황에 적합하게 최적화 될 수 있습니다. 예를 들어 (c)의 경우, 4개의 sub systolic array들로 분해된 것을 확인할 수 있는데 자주 Partial sum을 재활용 하는 경우 가장 효율적으로 이용될 수 있습니다. (a)의 경우는 중간 결과의 합 혹은 입력 값이 자주 재사용 되는 경우 효율적으로 이용될 수 있는 시나리오가 됩니다.
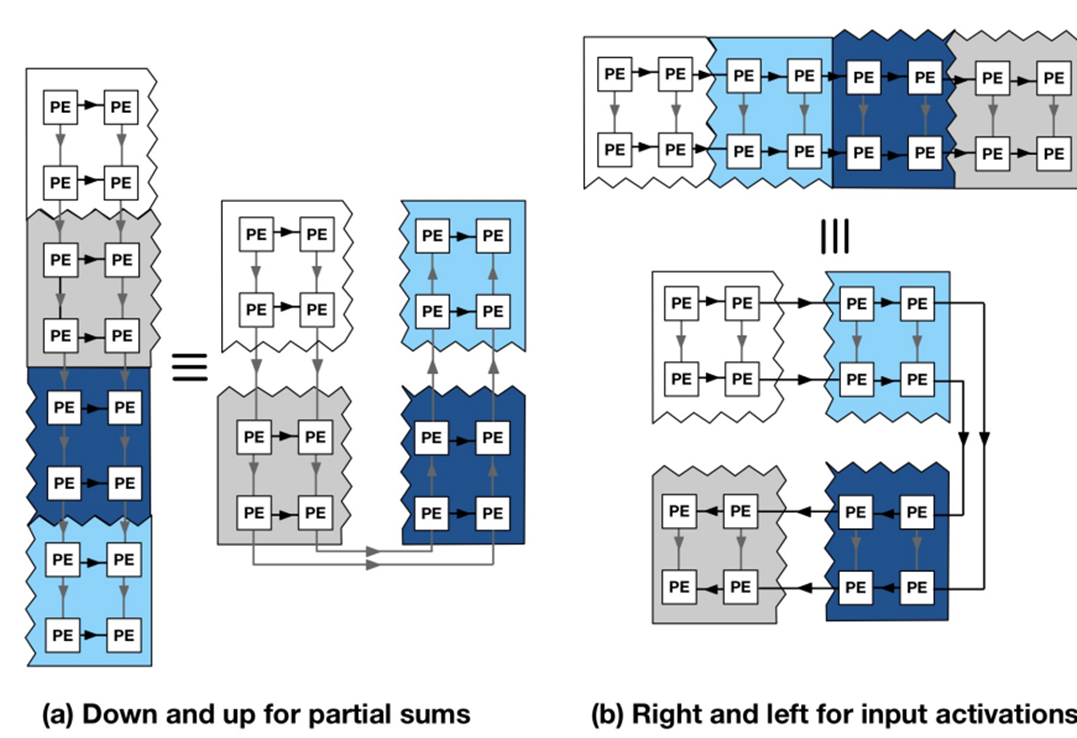
: 이를 통해 전방향으로 데이터가 이동하는 PE를 설계할 수 있었으며 Sub array들의 분할과 재결합을 통해 새로운 Data flow를 만들어낼 수 있었습니다. 하지만 기존의 Systolic array에서 PE를 전방향으로 바꾸어 새로운 데이터의 흐름을 만들어낸다고 하더라도 Input buffer들과 Output buffer들은 각 Sub array들과 상호 연결되어 있어야 합니다.
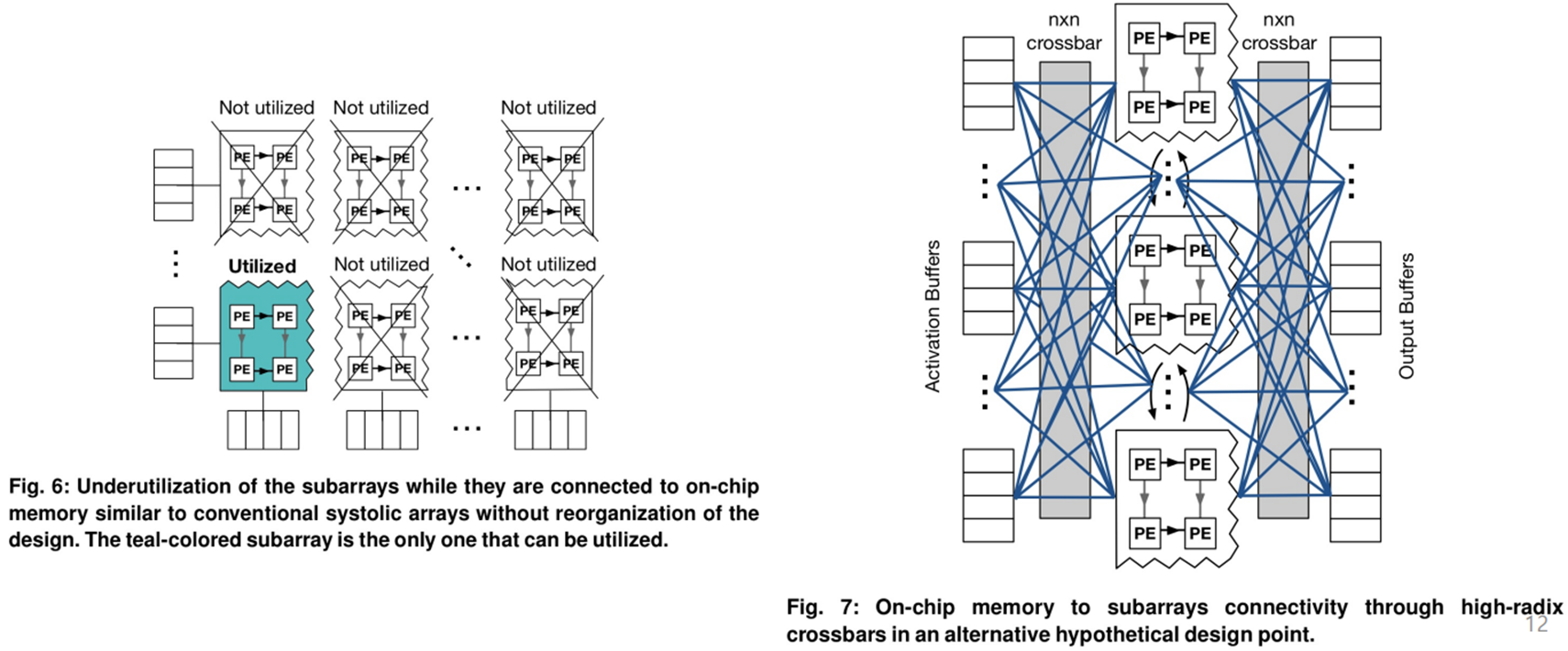
: 하지만 기존의 구조를 그대로 사용한다면 좌측에 보이는 것처럼 Input buffer와 Output buffer가 모두 연결되는 Sub array가 딱 한개만 존재할 수 있게 되며, 이를 해결하기 위해 오른쪽 그림처럼 각 Sub array들을 Buffer들과 wire로 모두 연결한다면, 이 상황에서도 매우 큰 자원 낭비가 발생합니다.

: 따라서 위에서 제기한 문제를 해결하기 위하여 아예 새로운 아키텍쳐의 도입이 필요합니다. Fission pod이라 불리는 이 구조는 4x4 Read/Write buffer들로 이루어져있으며 각 Sub array들은 Fission pod의 자원을 공유하게 됩니다. 4개의 Sub array들은 Fission pod이라 불리는 on-chip memory pod을 공유하며 각 Sub array들은 각각의 PE와 SIMD units을 갖고 있어 분할된 logical accelerator로써의 역할을 수행하게 됩니다. Fission pod은 각 Subarray들의 전방향 Systolic 실행을 가능하게 하며 ifmap과 psum을 공유합니다.
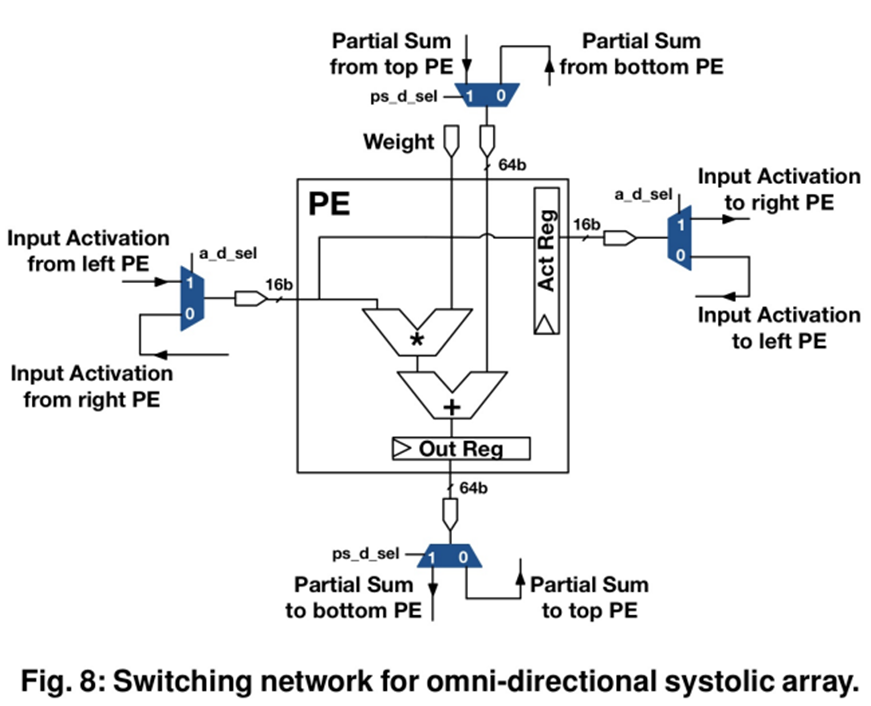
: 전 방향 Systolic array를 위해 Sub array 내부의 각 PE는 위와 같은 Switching network가 필요하게 됩니다.

: 위의 그림은 Planaria micro architecture의 구조를 설명하는 그림입니다.
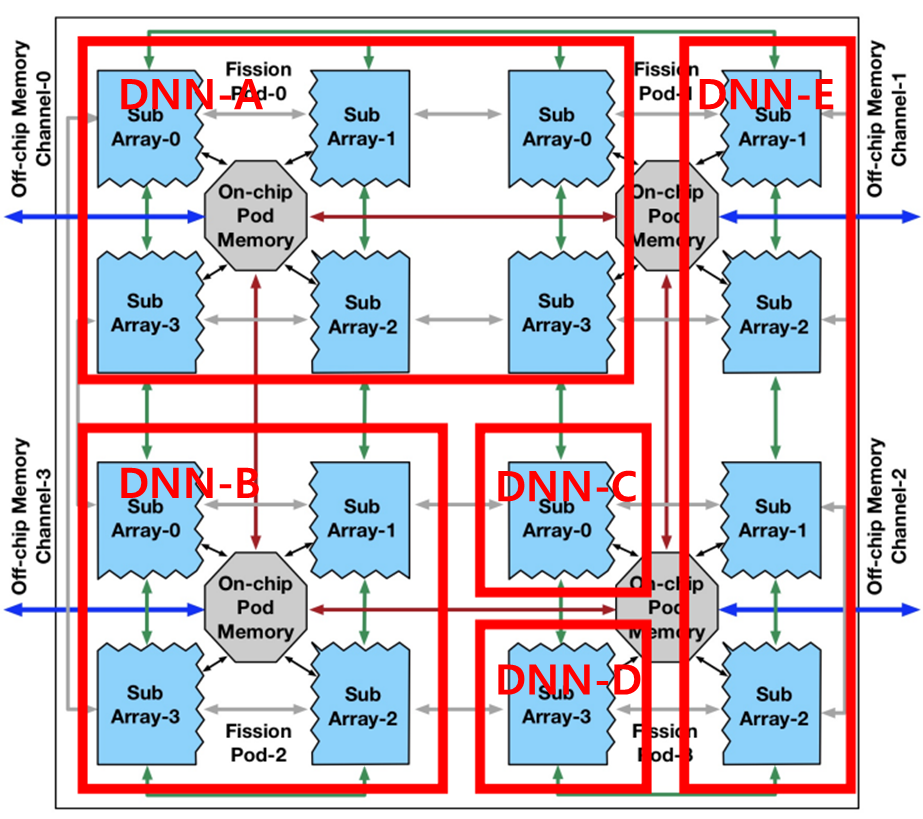
: 위의 Planaria architecture에서는 16개의 Sub array들이 존재할 수 있으며 이를 통해 65가지의 시나리오가 구현될 수 있습니다. 그림에서 볼 수 있는 빨간 박스들은 시나리오 중 하나를 설명하는 그림입니다. 그림과 같이 5개의 DNN Model들이 각 Logical accelerator에 할당되어 동시에 실행될 수 있게 됩니다.

: 앞서 설명한 Micro architecture에 여러 DNN Task들을 공간적으로 할당하기 위해서는 새로운 Scheduler의 도입이 필요합니다. 이 Scheduler는 세 가지의 요구 조건들을 충족해야합니다.
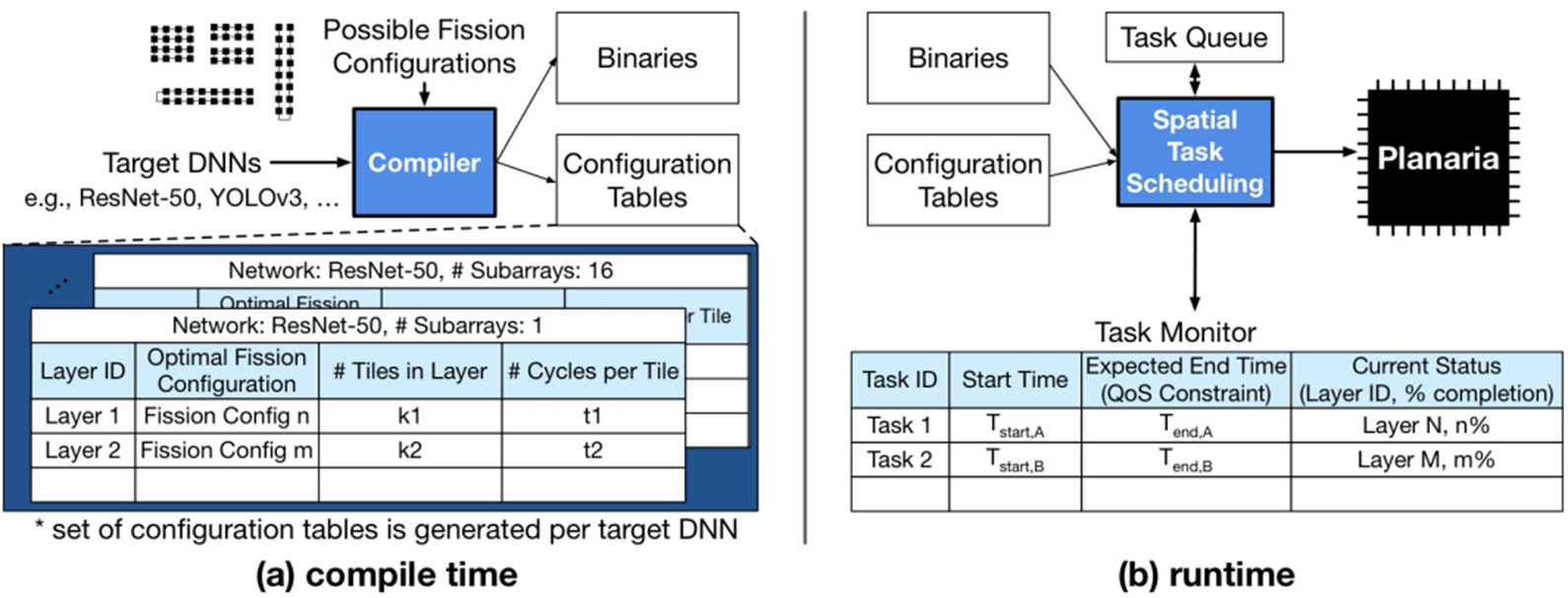
: 먼저 프로그램을 Compile할 때 실행할 Target DNN들을 어떤 시나리오로 가속기에 할당할지 결정해야 합니다. 이를 통해 컴파일러는 실행 파일과 Configuration table들을 생성합니다. 그 다음 실제 실행 시 Spatial Task Scheduler는 위 두 파일을 통해 처리할 Tast들을 실시간으로 Planaria architecture에 할당하게 됩니다.

: 다음 그림은 처리할 Task들이 도착하거나 끝난 경우에 어떤 순서로 처리되는지를 설명하는 그림입니다.
iii) Evaluation

: Planaria Architecture와 새로운 Scheduler를 설계하고 검증하기 위해 다음과 같은 환경을 조성하였습니다.

: 실험에는 세 가지의 INFaaS workload scenario들이 실행되었습니다. Multitenant 환경을 구현하기 위하여 Poisson distribution을 통해 각 요청에 대해 random한 arrival time을 부여하여 datacenter에서 발생할 수 있는 환경과 유사한 환경을 구축하였습니다. 또한 각 DNN benchmark들은 Planaria에서 compile 되었습니다.
Reference
[1] Kim, Moon Kwon, and Soo Dong Kim. "Inference-as-a-service: A situation inference service for context-aware computing." 2014 International Conference on Smart Computing. IEEE, 2014.